TL;DR Put this prompt into your AI Assistant: “I want to increase observability in my legacy project, and make it a critical component of all future development using speckit.”
If you’re managing an engineering team, you already know this pattern:
- An incident happens
- Multiple engineers jump into dashboards
- Debugging takes longer than expected
- The root cause is found—but only after significant effort
The issue isn’t a lack of data. It’s a lack of structured insight.
Combining AI with Speckit changes that dynamic in a very practical way:
it reduces time-to-understanding, not just time-to-detection.
The Real Gap: Data vs. Decision Speed
Most teams already have:
- Metrics (Prometheus, Datadog)
- Logs (ELK, CloudWatch)
- Traces (OpenTelemetry)
Yet incidents still drag on because:
- Signals aren’t structured around intent
- Context is missing or inconsistent
- Engineers must manually connect the dots
This creates two management problems:
- Long MTTR (Mean Time to Resolution)
- High cognitive load on senior engineers
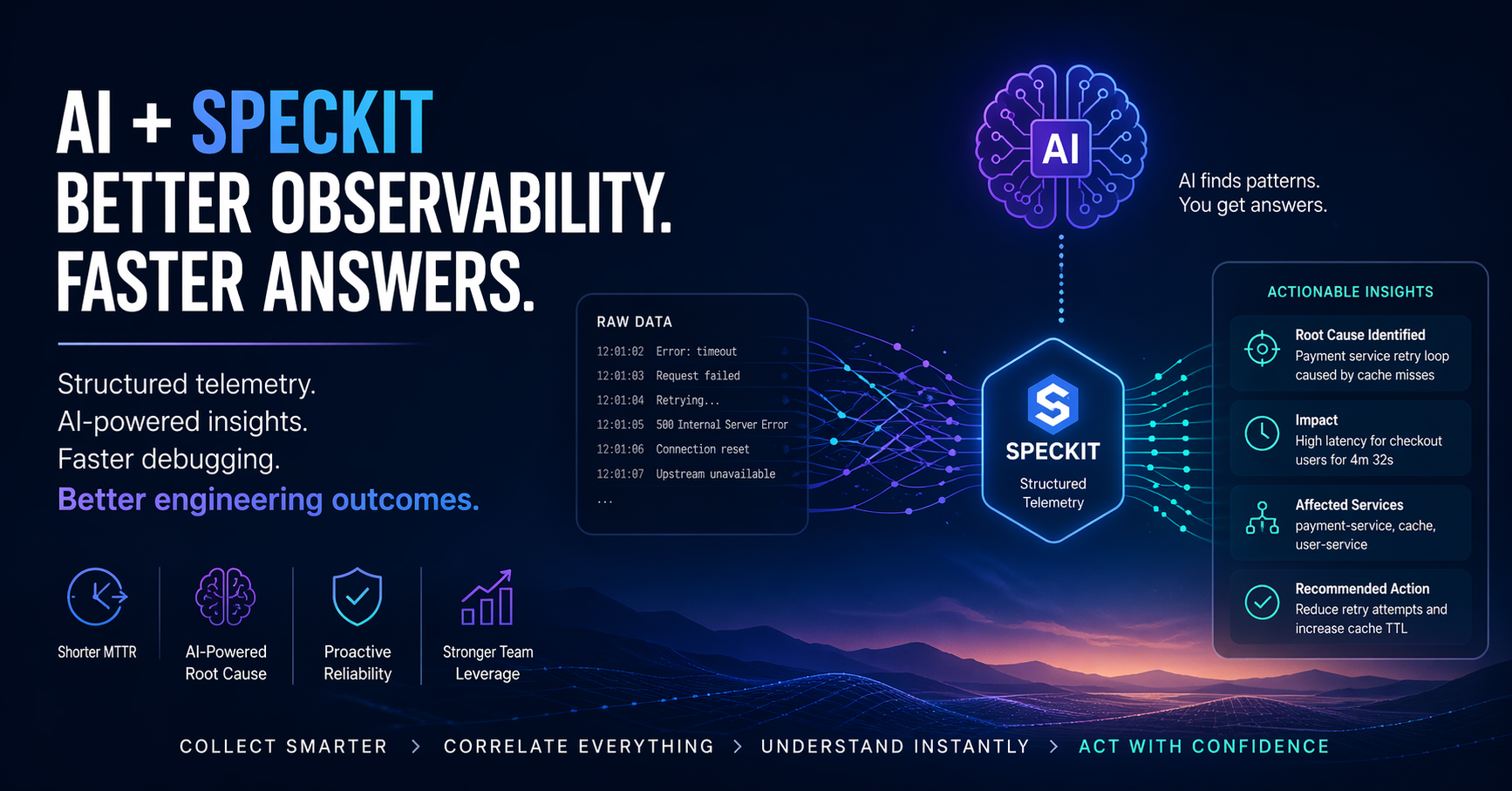
What Speckit Fixes
Speckit pushes teams to emit intentional, structured telemetry, not just raw logs.
Instead of:
"error": "timeout"
You get:
operation=checkout_payment
dependency=stripe_api
failure_mode=timeout
retry_attempt=2
user_impact=high
That structure is what makes AI actually useful—because now the system is machine-readable in a meaningful way.
Where AI Delivers ROI
Once telemetry is structured, AI becomes a force multiplier—not a gimmick.
Faster Root Cause Analysis
AI can:
- Correlate traces, logs, and metrics automatically
- Identify the most likely failure path PRECISELY
- Surface the actual cause, not just symptoms
Manager impact:
→ Incidents resolve in minutes instead of hours
→ Less reliance on your most senior engineers
Reduced Debugging Overhead
Instead of engineers acting as detectives:
- AI reconstructs the sequence of events
- Engineers validate and act
Manager impact:
→ Lower burnout
→ More consistent debugging quality across the team
Better Postmortems (Without Extra Work)
Structured telemetry + AI gives you:
- Clear timelines
- Causal chains
- Repeatable failure patterns
Manager impact:
→ Higher-quality learning
→ Fewer repeat incidents
Earlier Detection of Risk
AI can identify:
- Degrading dependencies
- Retry storms
- Latent bottlenecks
Manager impact:
→ Shift from reactive → proactive reliability
Concrete Architecture: How This Actually Fits Together
Here’s a practical, implementation-level view:
1. Instrumentation Layer (Speckit + OpenTelemetry)


- Services emit:
- Structured logs (Speckit conventions)
- Traces (OpenTelemetry)
- Metrics (standard exporters)
- Key idea:
Every event carries semantic context (operation, dependency, outcome).
2. Telemetry Pipeline
- Collectors (e.g., OpenTelemetry Collector)
- Routing to:
- Log storage (Elastic, Loki)
- Metrics (Prometheus)
- Traces (Jaeger, Tempo)
- Optional:
- Stream processing (Kafka, Kinesis) for real-time enrichment
3. AI Analysis Layer
This is the differentiator.
AI systems:
- Ingest structured telemetry
- Correlate across signals
- Build causal graphs
- Generate explanations
Typical outputs:
- “Root cause likely in payment service retry loop”
- “Latency driven by cache miss amplification”
4. Developer & Incident Interface
- Slack / PagerDuty integrations
- Dashboards with AI summaries
- Incident timelines auto-generated
Recommended Tooling for Java & Node
These are just examples for popular frameworks.
Core Observability
- OpenTelemetry (Java + Node)
- Foundation for traces, metrics, logs
- Standardizes everything
Java Stack
- OpenTelemetry Java SDK
- Spring Boot Actuator
- Logstash Logback Encoder
Tip:
Adopt structured logging early—don’t let teams ship plain text logs.
Node.js Stack
- OpenTelemetry JS
- Pino
- Winston
Tip:
Pino is faster and better suited for high-throughput services.
AI / Analysis Layer (Practical Options)
- Internal LLM pipelines over telemetry data
- Observability platforms with AI features (Datadog, Honeycomb, etc.)
- Custom pipelines using embeddings + trace correlation
What This Means for You as a Manager
This isn’t about “better tooling.” It’s about team leverage.
You get:
- Shorter incidents
- Less dependence on hero engineers
- More predictable delivery
- Better use of engineering time
You avoid:
- Debugging bottlenecks
- Burnout during incidents
- Repeated failures from poor visibility
The Bottom Line
Most teams invest in collecting more data.
That’s not the bottleneck.
The bottleneck is turning data into understanding quickly.
AI + Speckit does exactly that:
- Speckit ensures the data is meaningful
- AI ensures the meaning is surfaced instantly
If your systems can explain themselves, your team moves faster—with less stress.
And that’s a management win, not just a technical one.
Leave a Reply